Kubernetes关键知识点(一)
前言
Kubernetes 是业界最火热的容器编排平台,主要用于管理容器化的工作负载和服务,已经成为云原生应用的基石。
关于云原生的技术介绍可以参考前一篇文章:不好意思说自己不知道云原生了
架构设计
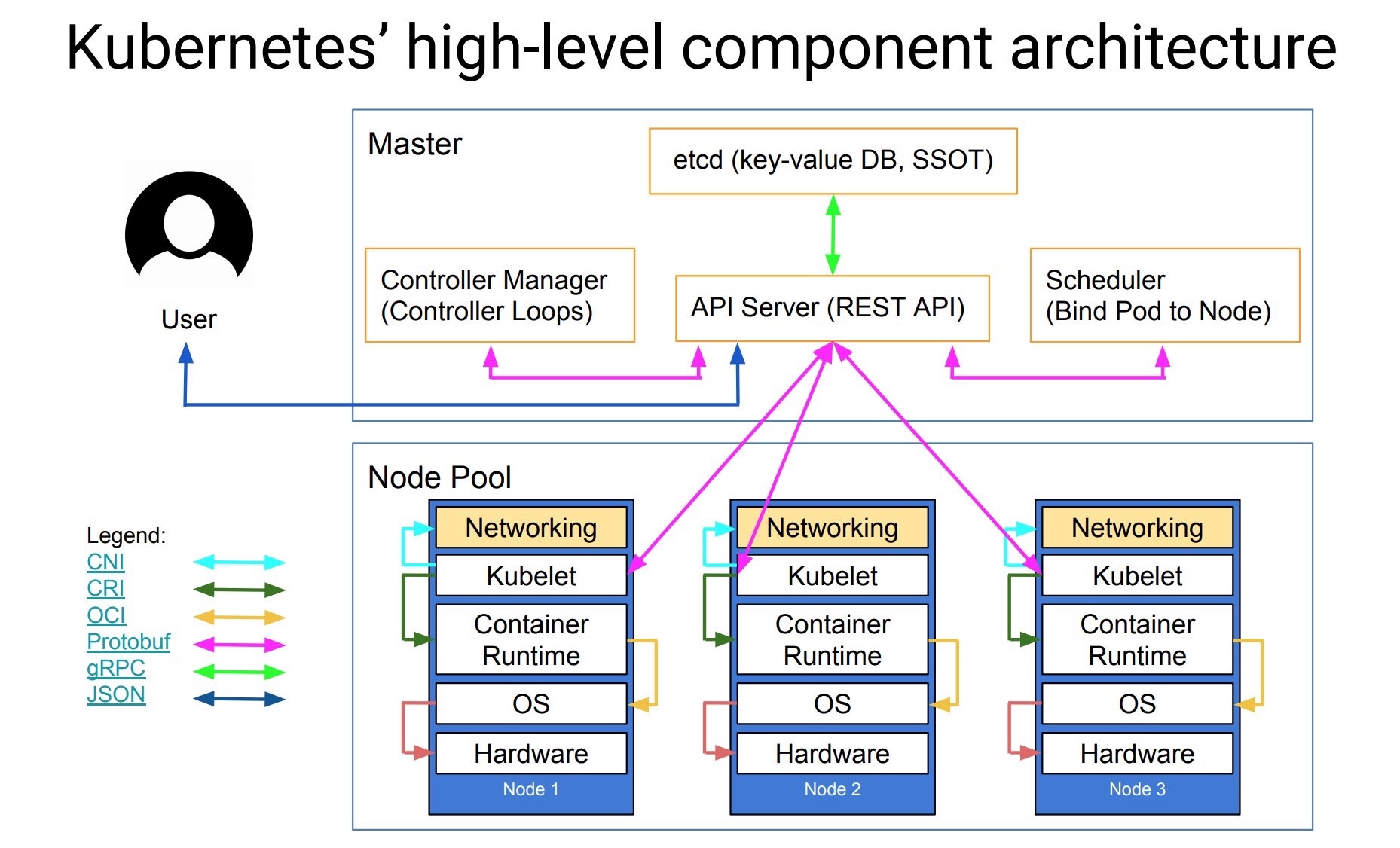
Kubernetes 的核心组件:
- kube-apiserver:资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制。
- controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等。
- kube-scheduler:负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上。
- kubelet:负责维护容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理。
- Container runtime:负责镜像管理以及 Pod 和容器的真正运行(CRI)。
- kube-proxy:负责为 Service 提供 Cluster 内部的服务发现和负载均衡。
- etcd:保存整个集群的状态。
核心概念
Pod
-
什么是Pod?
Pod 是 Kubernetes 中的最小的部署单元,它由一组容器组成, 可能包含一个或者多个密切相关的应用。Pod 中容器只能部署在同一台机器,所有容器共享同一个 IP 地址和端口,可以通过 localhost 相互访问,也可以通过标准的进程间通信方式访问。
-
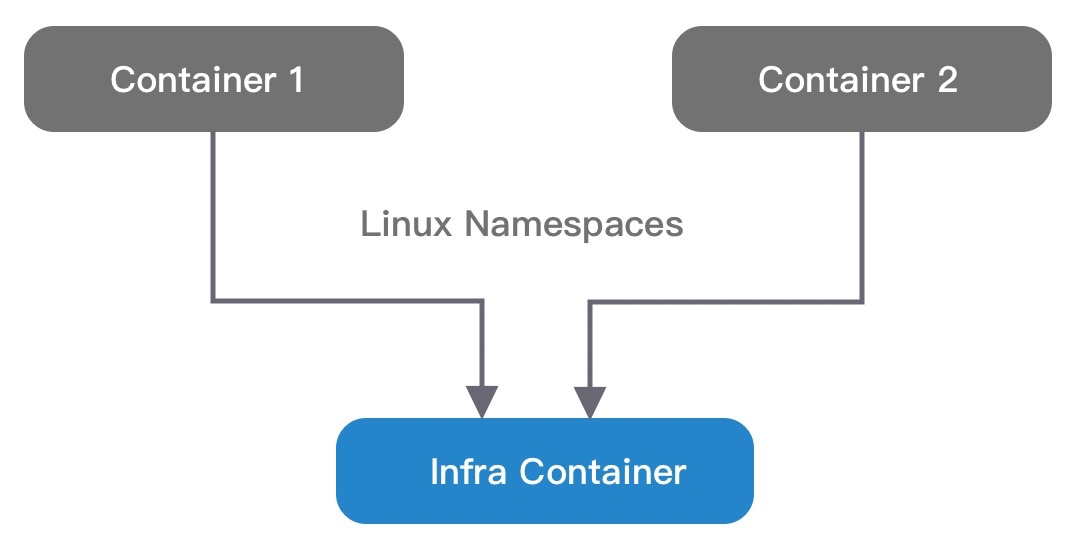
实现方式 —— infra容器:pause
docker ps 查看容器列表时,发现有很多 pause 容器在运行,这些容器是在做什么呢?为了让容器之间共享 Network、IPC 等,实现的方式是先启动一个容器,其他的容器的 Namespace 该容器的 Namespace 设置为相同。pause 容器就是专门为了实现这个效果而设计的,它非常轻量,随 Pod 启动创建,其他容器启动与自身共享 Namespace。容器启动完成后 pasue 容器暂停,不消耗资源。
Node
Node 是执行工作的机器,它可以是物理机、也可以是虚拟机,Kubernetes 是不关心机器配置的,不同的机器都可以被抽象为 Node。
不同 Node 上的 Pod 的网络是互通,这是 Kubernetes 的规范,可以通过不同的网络插件实现,如Flannel、Calico 等。
Pod 与 Node 关系?
ReplicaSet
目前官方已经推荐使用 Deployment 和 ReplicaSet(RS) 来替代 ReplicationController,RS 的 3 个重要组成部分:
- replicas 副本个数
- label selector 标签选择器
- pod template
RS 用于控制任何时刻 Pod 副本的数量,并保证 Pod 是可用的,RS 是通过标签来管理 Pod:
- 手动删除 Pod 标签,RS 会重新创建新的 Pod,删除标签的 Pod 不再受 RS 控制。
- 手动为某个 Pod 加上对应标签,RS 将删除一个 Pod,保持 Pod 的数量与预期是一致的。
Deployment
Deployment是基于 ReplicaSet 来实现 Pod 的自动化管理。为什么 RS 不能实现?RS 只管理 Pod 标签,更新 Pod template,是不会重新部署 Pod 的,只会对新创建的 Pod 生效。Deployment 不仅具备 RS 的所有特性,而且具备事件状态、版本记录、回滚等更加丰富的特性。
Deployment 如何扩缩容?
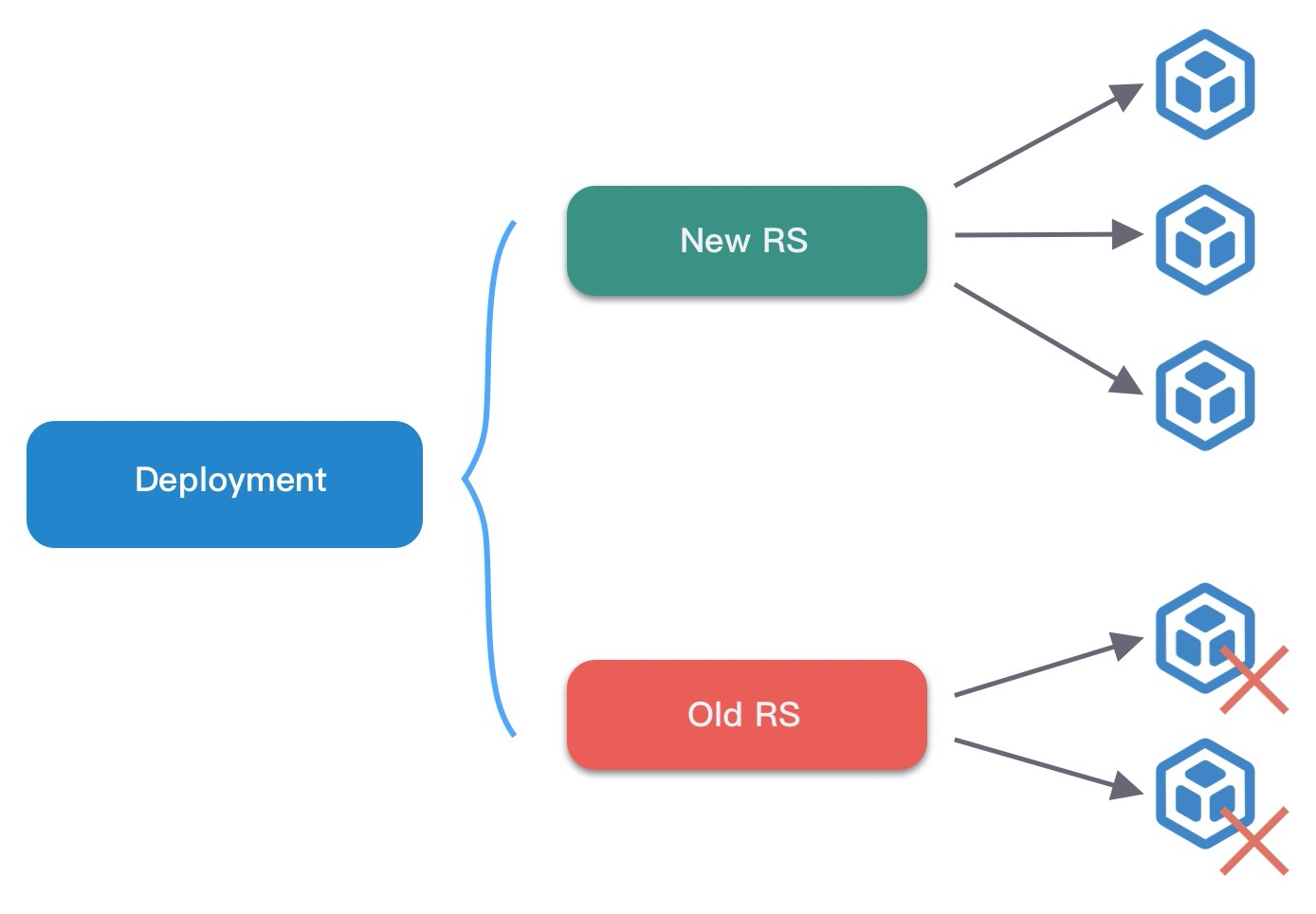
Deployment 滚动更新时,如果存在多个可用的 RS,那么会按比例对多个 RS 进行扩缩容。滚动更新用到的几个参数:
- maxSurge 最多比期望 Pod 数量多出的 Pod 数量
- maxUnavaible 最多多少 Pod 可以处于不可用状态
- minReadySeconds 等待设置的时间后再进行升级
StatefulSet
StatefulSet 用于管理有状态的 Pod,可以保证 Pod 的顺序性和不变性。
-
顺序性
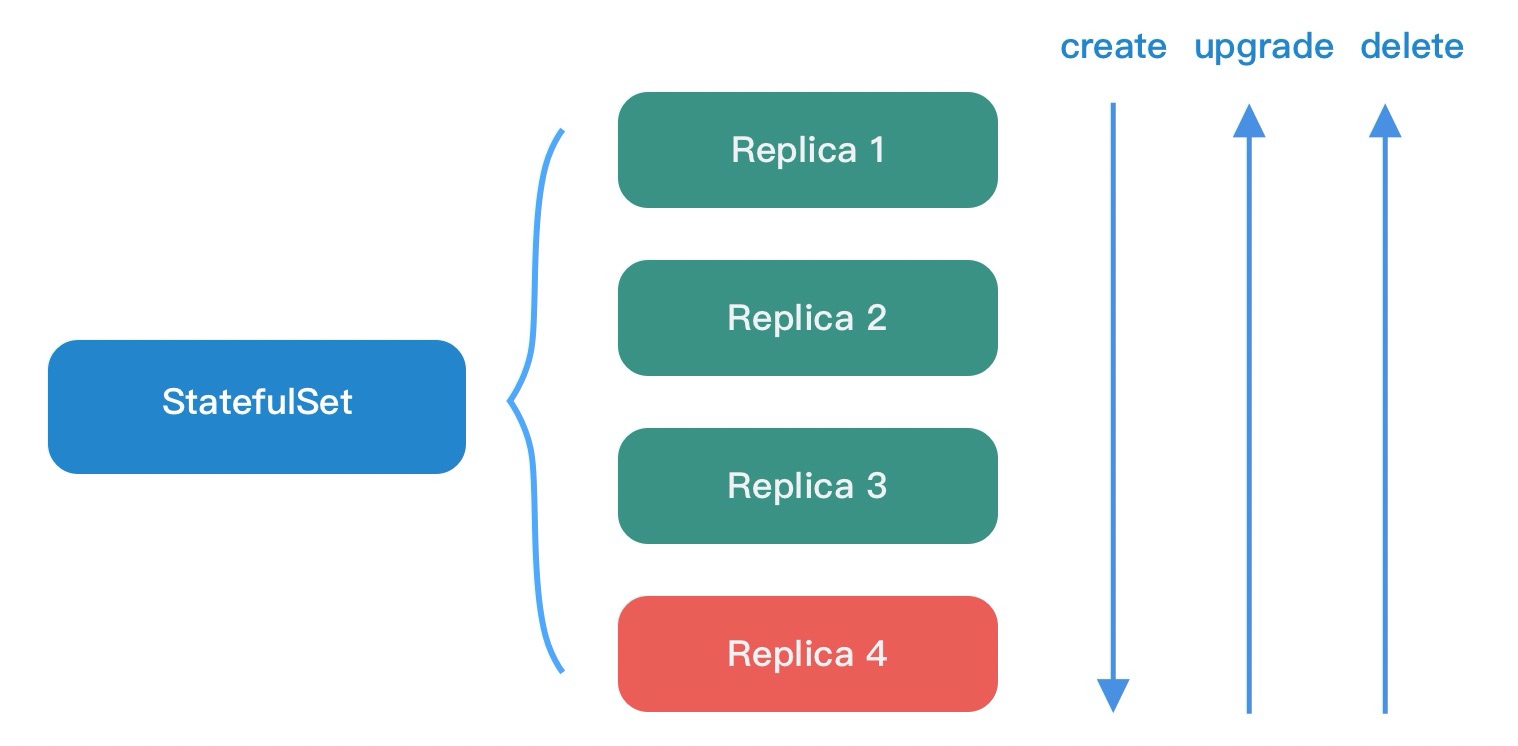
-
不变性
- Pod 身份标识:Pod 名称、IP 地址等。StatefulSet 中 Pod 名称是以数字顺序编号的,重建 Pod 会使用与之前相同的名称。
- 存储不变:依赖 PV、PVC 实现,在此先不展开。
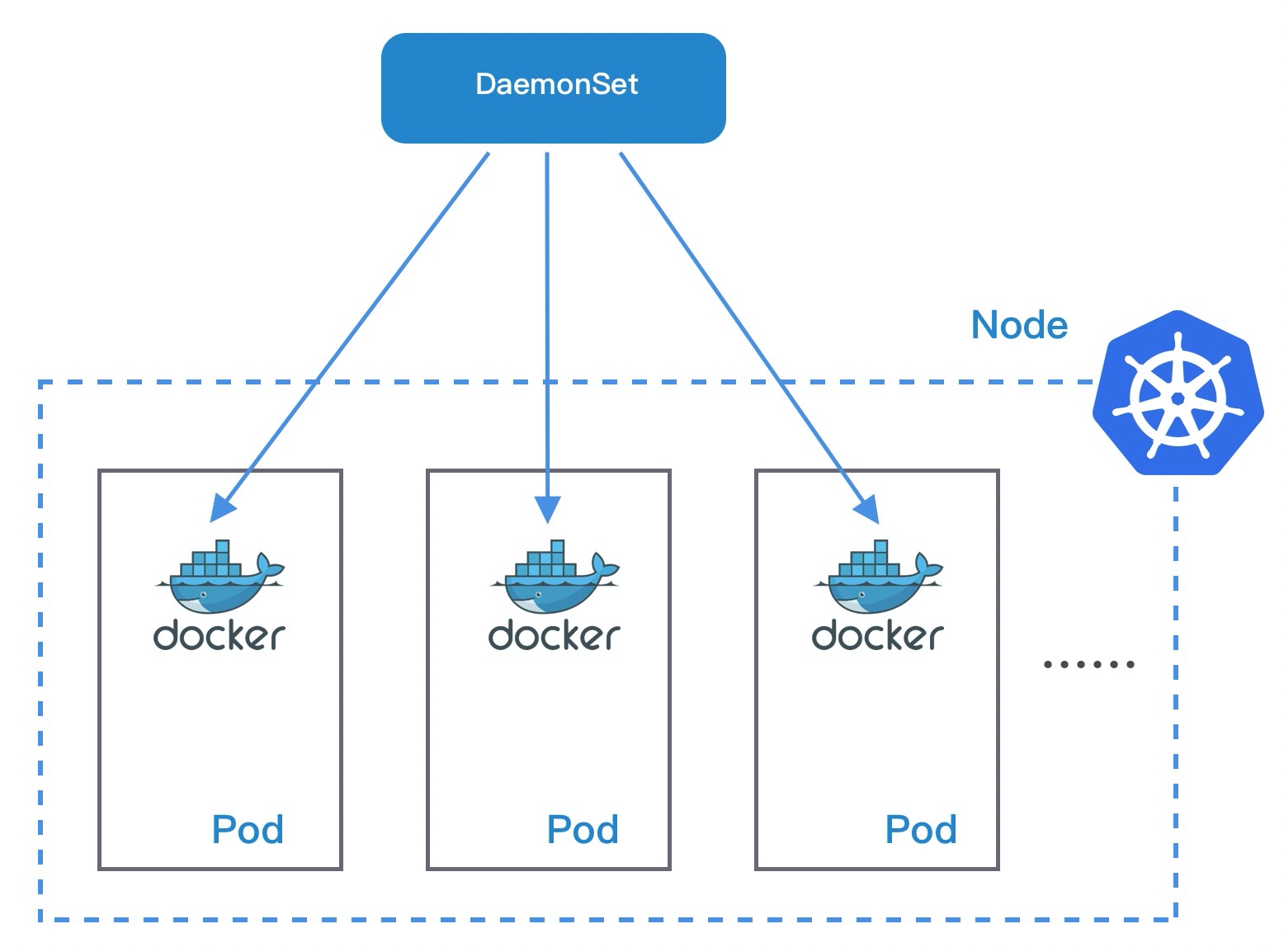
DaemonSet
DaemonSet 保证在每个节点上都运行一个容器副本,通常用于日志采集、监控以及运行系统应用等场景。当有新的节点加入集群时,DaemonSet 所管理的 Pod 就会在该节点创建;如果节点从集群中剔除,Pod 也会相应删除。
Static Pod
kubelet 在启动时,–pod-manifest-path 以及 –manifest-url 参数配置的目录下所定义的 Pod 都会自动创建。kubelet 会定期扫描配置目录下的文件,当有文件创建或删除时会触发对应 Pod 的创建和删除动作。
ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
可以看到 Kubernetes 的四大件都是以 Static Pod 的形式运行,这些 Pod 是不受 apiserver 控制的,而且 apiserver 也不可能自己控制自己。
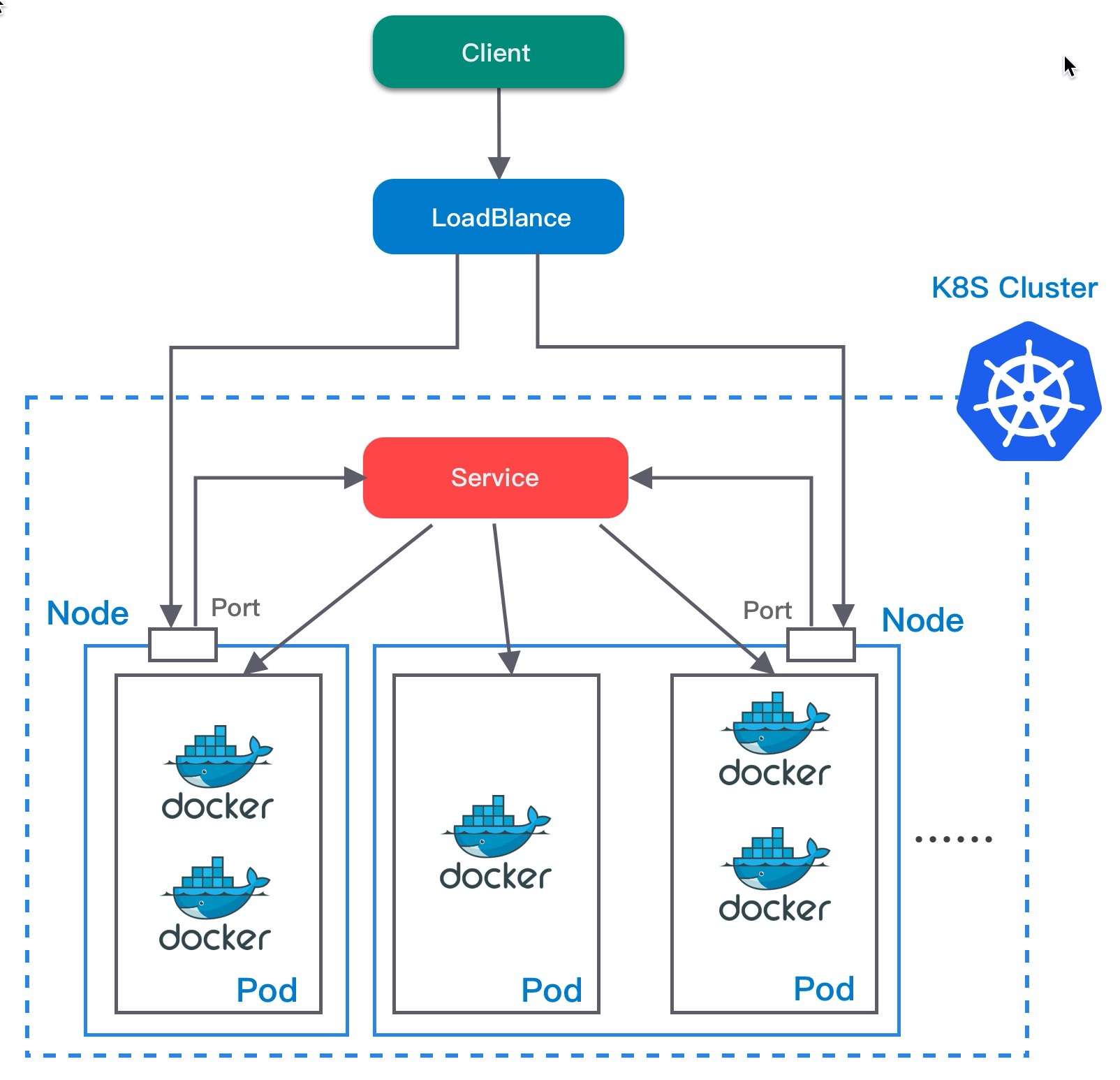
Service
Pod 需要对外提供服务,Service 类似 VIP、软负载、网关等功能,它实现了对一组 Pod 的访问方式的抽象,Service 也是通过标签来寻找对应的 Pod。
Pod 的 IP 地址是经常变化的,Service 为一组 Pod 提供了统一入口,这样前端就不需要关心使用的是哪个后端服务以及后端服务的列表是什么,Service 已经帮我们解决了类似服务发现的问题。
-
Service 的类型
-
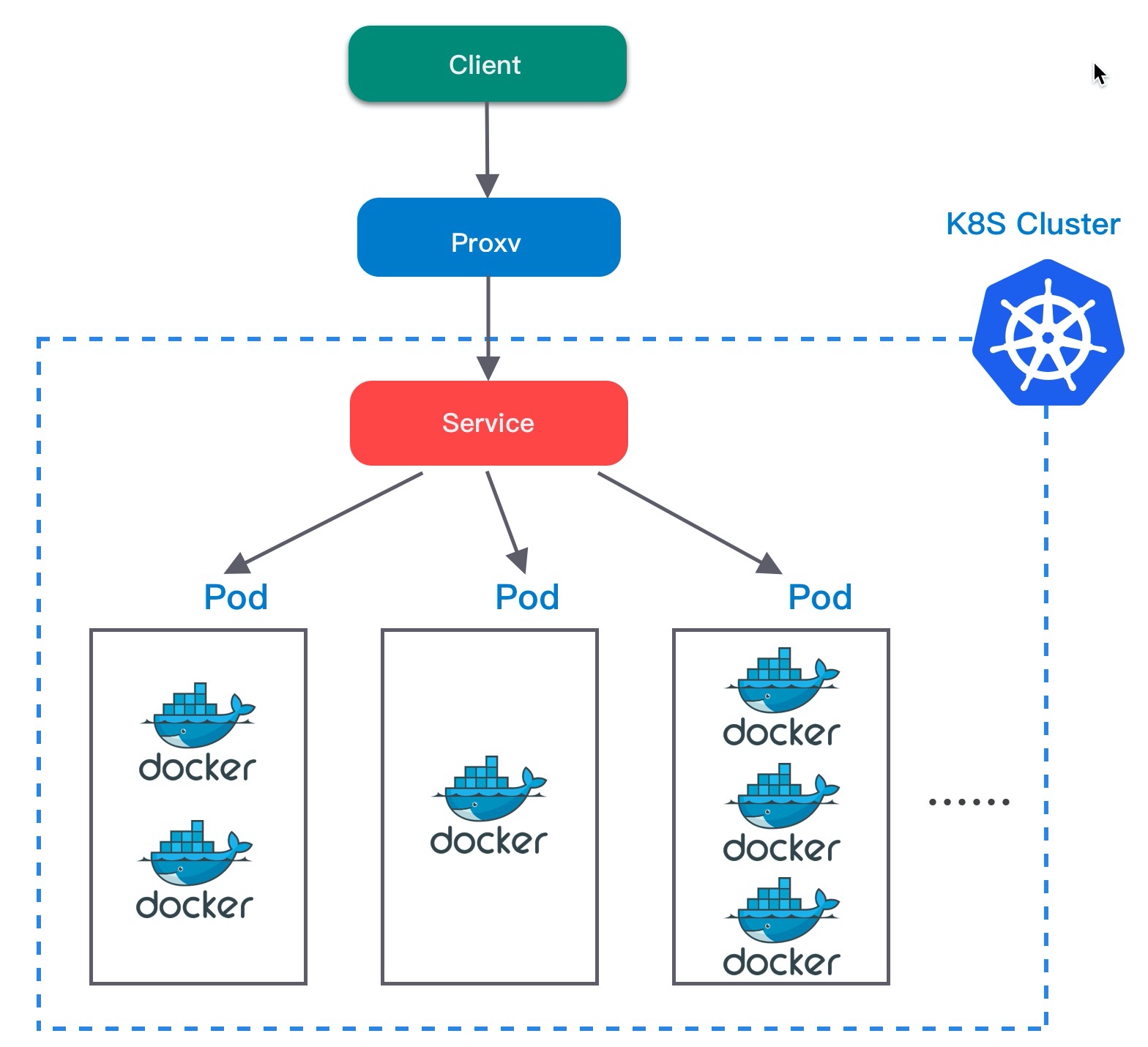
ClusterIP
ClusterIP 是默认的 Service 类型, 只能用于集群内部通信,Kubernetes 会为每个 Service 分配一个虚拟 IP(ClusterIP)。
-
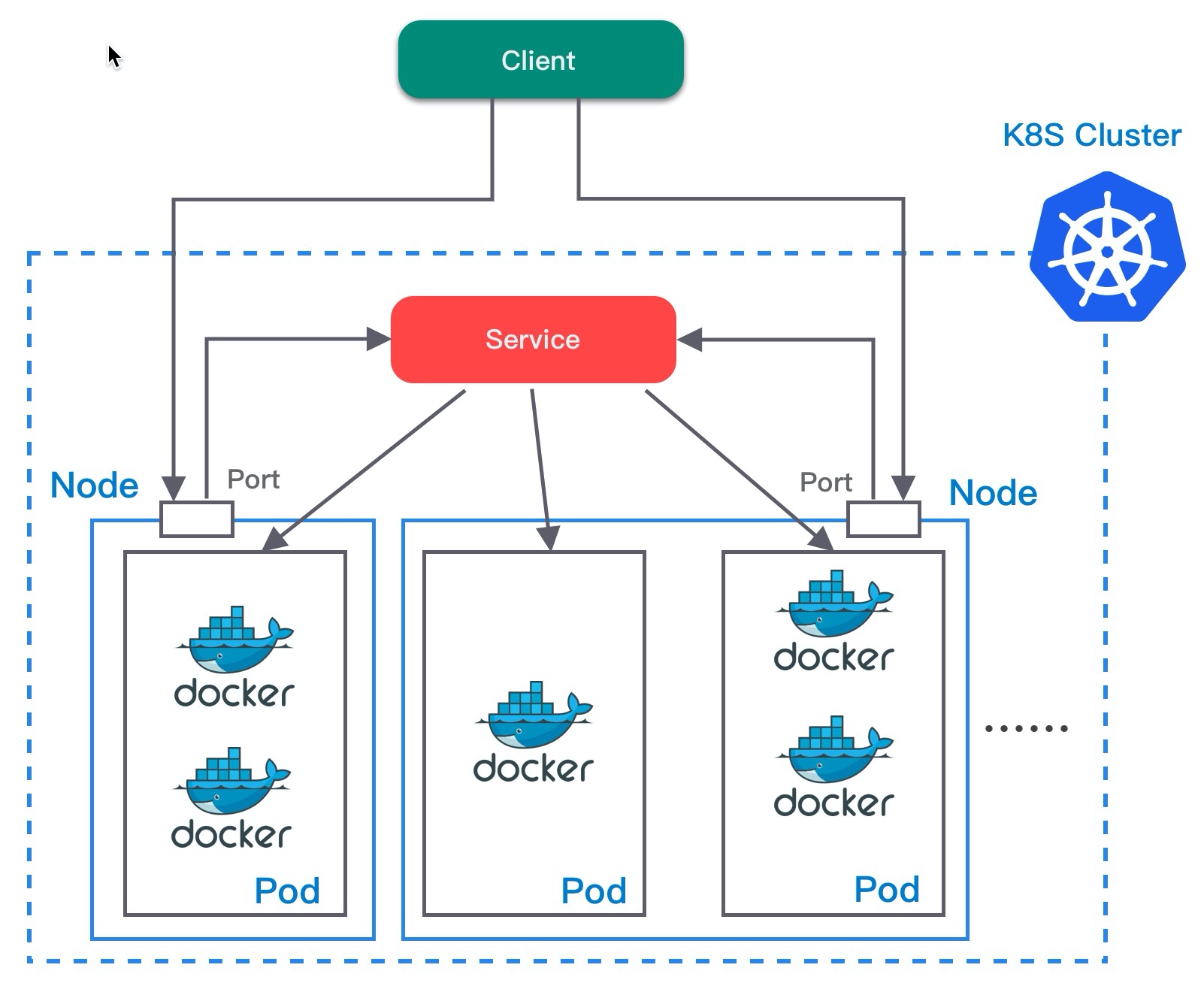
NodePort
NodePort 类型会在集群内所有节点上开放指定端口。外部客户端首先会访问节点上对应的端口,然后转发到服务的 IP 上。
-
LoadBalancer
LoadBalancer 类型通常是将 Service 和第三方云厂商提供的 LoadBalancer 产品结合在一起使用,它是通过在 NodePort 前挂上 LoadBalancer 来实现,可以将集群内部服务暴露到外网。
-
ExternalName
ExternalName 类型的 Service 为外部 DNS 名称提供内部别名,可以将服务映射到 externalName 字段的内容。内部客户端使用内部 DNS 名称发出请求,会被重定向到外部名称。(用的很少)
-
-
Headless Service 又是什么?
Headless Service 也是一种 Service,不同的是它不需要 ClusterIP(没头的 Service),kube-proxy 不会对其进行处理。
- 访问服务的时候回会返回所有的后端 Pods IP 地址,开发者可以根据需求进行负载均衡的扩展。
- Headless Service 对应的每一个Endpoints 都有对应的 DNS 域名, Pod 之间可以互相访问。
Ingress
Ingress 作用在 7 层,类似 nginx、haproxy 等负载均衡的代理服务器,它为 Kubernetes 提供了集群外部的访问入口,将外部流量转发到集群内不同的 Service,可以根据不同的 URL 规则转发到不同的 Service。
集群必须有一个或者多个 Ingress Controller 才能保证 Ingress 功能的正常使用,Ingress Controller 通过 apiserver 感知 Service 和 Pod 的变化,然后根据 Ingress 配置更新反向代理已达到服务发现的目的。


