系统优化总结
之前组内一位大佬分享了一些关于系统性能优化方面的干货,这里我将它整理成文并且加入自己平时常用的一些工具和技巧。由于关于系统性能优化涉及的内容非常多,我会分几篇文章来分享。这次分享下定位系统层面问题的常用方法。
系统性能定义
- Throughout 吞吐量 (系统每秒钟可以处理的请求数)
- Latency 延迟 (系统处理一个请求的延迟)
- Usage 资源利用率
吞吐量和延迟的关系
- 吞吐量越高,延迟会越大。因为请求量过大,系统太繁忙,所以响应时间会降低。
- 延迟越小,能支持的吞吐量会越高。因为延迟短说明处理速度快,就可以处理更多的请求。
异步化可以提高系统的吞吐量的灵活性,但是不会获得更快的响应时间。
系统性能压测的常用工具
tcpdump
1. 常用参数:
-i:指定需要的网
-s:抓取数据包时默认抓取长度为68字节,加上-s 0后可以抓到完整的数据包
-w:监听的数据包写入指定的文件
2. 示例
tcpdump -i eth1 host 10.1.1.1 // 抓取所有经过eth1,目的或源地址是10.1.1.1的网络数据包
tcpdump -i eth1 src host 10.1.1.1 // 源地址
tcpdump -i eth1 dst host 10.1.1.1 // 目的地址
如果想使用wireshark分析tcpdump的包,需要加上是 -s 参数:
tcpdump -i eth0 tcp and port 80 -s 0 -w traffic.pcap
tcpcopy——线上引流压测
tcpcopy是一种请求复制工具,用于实时和离线回放,它可以将线上流量拷贝到测试机器,实时模拟线上的真实环境,达到程序不上线的情况下承担线上真实流量的测试。实战演习的必备工具。
a. tcpdump录制pace文件
tcpdump -i eth0 -w online.pcap tcp and port 80
b. 流量回放
tcpcopy -x 80-10.1.x.x:80 -i traffic.pcap
tcpcopy -x 80-10.1.x.x:80 -a 2 -i traffic.pcap // 离线回放加速2倍
c. 引流模式
tcpcopy -x 80-10.1.x.x:80 -r 20 // 20%引流
tcpcopy -x 80-10.1.x.x:80 -n 3 // 放大三倍引流
wrk & ApacheBench & Jmeter & webbench
个人非常推荐wrk,轻量且压测结果准确,结合Lua脚本可以支持更复杂的测试场景。
压测示例:4个线程来模拟1000个并发连接,整个测试持续30秒,连接超时30秒,打印出请求的延迟统计信息。
> wrk -t4 -c1000 -d30s -T30s --latency http://www.baidu.com
Running 30s test @ http://www.baidu.com
4 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.71s 3.19s 26.51s 89.38%
Req/Sec 15.83 10.59 60.00 66.32%
Latency Distribution
50% 434.52ms
75% 1.70s
90% 5.66s
99% 14.38s
1572 requests in 30.09s, 26.36MB read
Requests/sec: 52.24
Transfer/sec: 0.88MB
更多参数帮助信息:
> wrk --help
Usage: wrk <options> <url>
Options:
-c, --connections <N> Connections to keep open
-d, --duration <T> Duration of test
-t, --threads <N> Number of threads to use
-s, --script <S> Load Lua script file
-H, --header <H> Add header to request
--latency Print latency statistics
--timeout <T> Socket/request timeout
-v, --version Print version details
Numeric arguments may include a SI unit (1k, 1M, 1G)
Time arguments may include a time unit (2s, 2m, 2h)
定位性能瓶颈
可以从以下几个方面衡量系统的性能:
- 应用层面
- 系统层面
- JVM层面
- Profiler
应用层面
应用层面的性能指标:
- QPS
- 响应时间,95、99线等。
- 成功率
系统层面
系统层面指标有Cpu、内存、磁盘、网路等,推荐用一个犀利的命令查询系统性能情况:
dstat -lcdngy
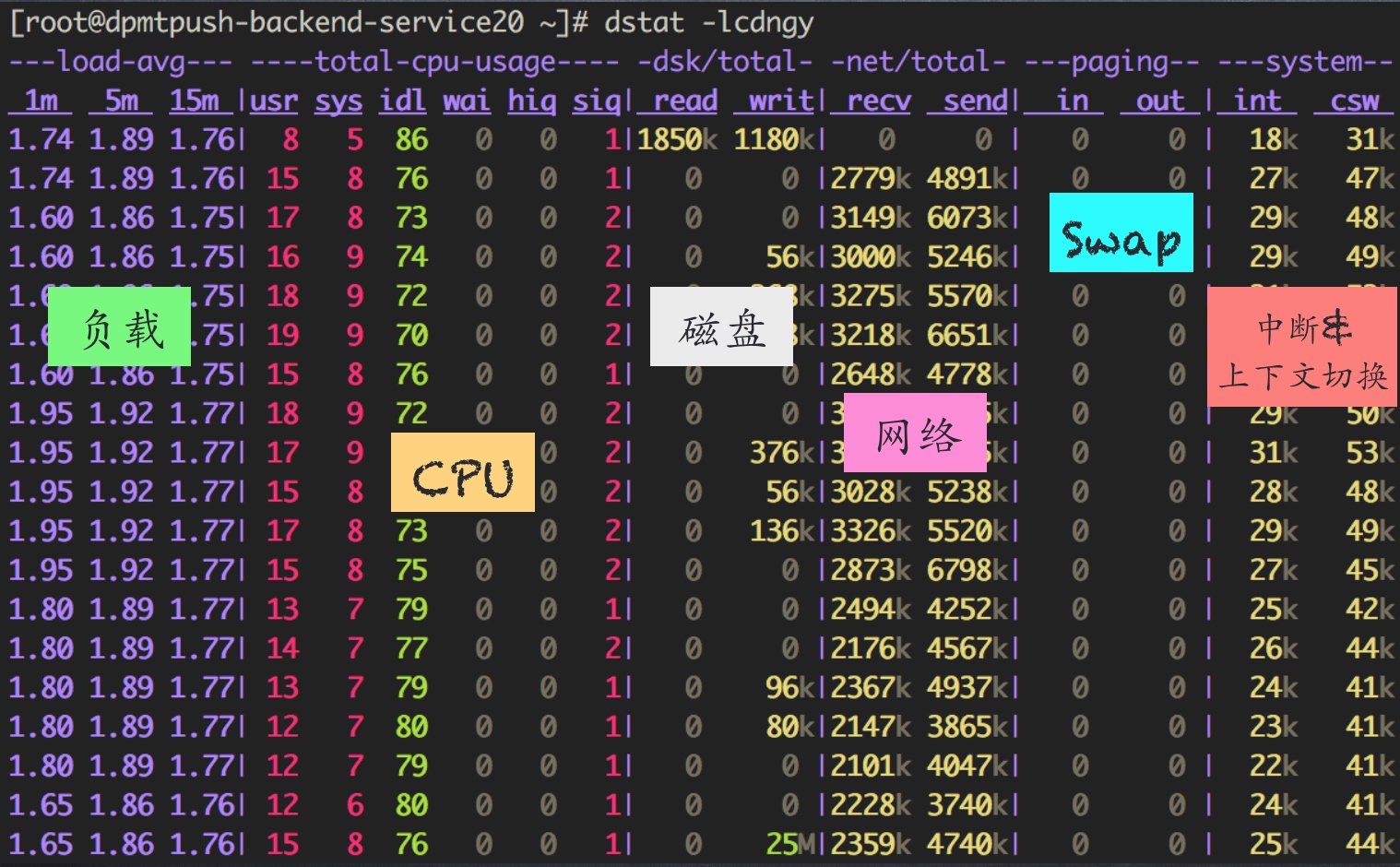
dstat非常强大,可以实时的监控cpu、磁盘、网络、IO、内存等使用情况。
- 安装方法
yum install -y dstat
- 功能说明
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。 -D hda,total:include hda and total。
-n:显示网络状态。 -N eth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcp udp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于 -pmgdsc -D total。
--output 文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
Cpu
-
使用率:Cpu是最重要的资源,如果CPU在等待,也会导致Cpu高使用率。
CPU利用率 = 1 - 程序占用cpu时间/程序总的运行时间 -
用户时间/内核时间:大致判断应用是计算密集型还是IO密集型。
CPU花在用户态代码的时间称为用户时间,而执行内核态代码的时间称为内核时间。内核时间主要包括系统调用,内核线程和中断的时间。当在整个系统范围内进行测量时,用户时间和内核时间之比揭示了运行的负载类型。计算密集型应用会把大量时间花在用户态代码上,用户时间/内核时间之比接近99/1。这样的例子有图像处理,数据分析等。I/O密集型应用的系统调用频率较高,通过执行内核代码进行I/O操作。一个进行网络I/O的Web服务器的用户/内核时间比大约为70/30。
-
负载load:在特定时间间隔内运行队列中的平均进程数。每个CPU都有一个运行队列,队列里存放着已经就绪,等待被CPU执行的线程。
理想状态下,希望负载平均值小于等于Cpu核数。
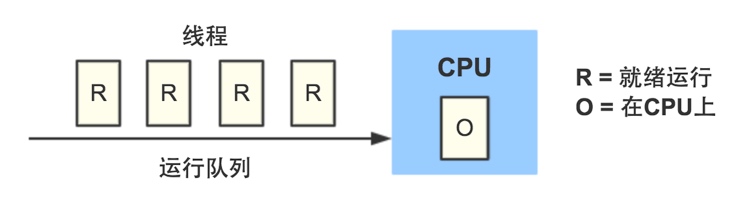
Cpu使用率和load的区别:
- 负载均值用来估量CPU利用率的发展趋势,而不是某一时刻的状况。
- 负载均值包括所有CPU的需求,而不仅仅是在测量时活跃的。
磁盘
磁盘空间:没有空间会导致程序无法启动或者报错。
du -sh //查看当前文件夹下所有文件大小
df -hl //以磁盘分区为单位查看文件系统
有时候linux服务器的系统日志文件过大导致磁盘使用率过高,推荐两种清理方式:
sudo /dev/null > /var/log/**.log //删除指定的较大日志文件,速度快
sudo find /var/log/ -type f -mtime +30 -exec rm -f {} \ //删除30天之前的日志文件
磁盘权限:没有权限会导致程序无法启动或者报错。
ll /yourdir
磁盘性能测试
dd if=/dev/zero of=output.file bs=10M count=1
io吞吐、iowait
这里重点说下这两个因素,大量的磁盘读写以及过高的iowait往往意味着磁盘可能是瓶颈。实际上iowait并不能反映磁盘成为性能瓶颈,它实际测量的是cpu的时间:
%iowait = (cpu idle time)/(all cpu time)
所以唯一定位磁盘成为性能瓶颈的直接方法还是看read/write时间。下面我们着重介绍下如何定位io问题。
a. 宏观确定是否是io的问题:top命令,可以从Cpu这一行看出浪费在I/O Wait上的CPU百分比;数值越高代表越多的CPU资源在等待I/O权限。

b. 确定具体磁盘问题:iostat

%util直观地反应可哪一块磁盘正在被写入,反应了设备的繁忙程度。每毫秒读写请求(rrqm/s wrqm/s)以及每秒读写(r/s w/s)对排查问题也提供了很多有用的信息。
c. 确定具体进程:简单粗暴的iotop直观地反映了哪些进程是导致io问题的罪魁祸首。

d. ps判断进程是否等待IO一样强大
众所周知,ps命令为我们提供了内存、cpu以及进程状态等信息,根据进程状态可以很容易查到正在等待IO的进程信息。
这里简单说下linux进程的几种状态:
- R (TASK_RUNNING),可执行状态。
- S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
- D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
- T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
- Z (TASK_DEAD – EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
- X (TASK_DEAD – EXIT_DEAD),退出状态,进程即将被销毁。
其中等待I/O的进程状态一般是”uninterruptible sleep”即D状态,D状态以及R状态进程算为运行队列之中,所以D状态进程过多也会导致系统load偏高,有兴趣可以看下linux load的计算原理。
查看D状态进程:
> for x in `seq 1 1 10`; do ps -eo state,pid,cmd | grep "^D"; echo "--------"; sleep 5; done
D 13389 /usr/libexec/gcc/x86_64-redhat-linux/4.4.7/cc1 -quiet -I../../include/cat -I../ -I. -dD message_sender.c -quiet -dumpbase message_sender.c -mtune=generic -auxbase message_sender -ggdb3 -O2 -O0 -o /tmp/ccivsNPE.s
根据proc伪文件系统获取io相关信息:
> cat /proc/pid/io
rchar: 548875497
wchar: 270446556
syscr: 452342
syscw: 143986
read_bytes: 253100032
write_bytes: 24645632
cancelled_write_bytes: 3801088
e. 确定哪个文件频繁读写:lsof -p pid
网络
1. nestat
netstat -nt 查看tcp相关连接状态、连接数以及发送队列和接收队列

关于tcp的状态需要大家熟悉三次握手和四次挥手的过程,这里先列出tcp的全部状态。
客户端:SYN_SENT、FIN_WAIT1、FIN_WAIT2、CLOSING、TIME_WAIT
服务端:LISTEN、SYN_RCVD、CLOSE_WAIT、LAST_ACK
Common:ESTABLISHED、CLOSED
Tcp状态变化图(摘自网络):
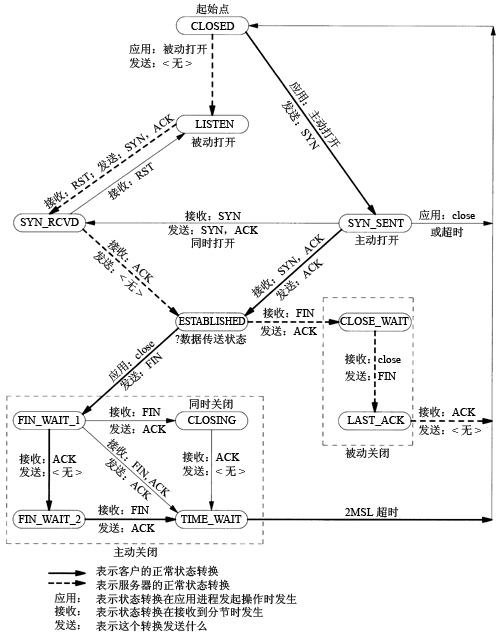
关于tcp状态的几点说明:
- 正常的连接应该是ESTABLISHED状态,如果存在大量的SYN_SENT的连接,则需要看下防火墙规则。
如果Recv-Q或者Send-Q持续有大量包存在,意味着连接存在瓶颈或者程序存在bug。
2. 一些其他常用技巧
关于netstat还有很多有用的技巧,这里列出平时比较常用的:
netstat -nap | grep port 显示使用该端口的所有进程id
netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn 查询全部状态并排序
awk '{print $1}' access.log |sort|uniq -c|sort -nr|head -10 分析access.log获取访问做多的top n的ip地址
netstat -nat | grep "10.1.1.1:8080" |awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -20 连接某服务器最多的top n的ip地址
netstat -s 如果重传的包持续增加,那么很大可能网卡存在问题
JVM
定位问题的杀手锏——线程堆栈
1. 获取线程堆栈的步骤:
ps -ef | grep java
sudo -u nobody jstack <pid> > /tmp/jstack.<pid>
小技巧:jstack信息是某个时刻的堆栈信息,有时间仅仅一个jstack并不能分析出问题所在,可以适当多几次jstack,然后进行对比分析。
2. 如何从线程堆栈中找到本地线程对应的id

nid=native thread id,特殊的是nid使用十六进制标识,本地线程id是十进制标识,所以通过进制换算就可以讲两者对应起来。
16进制和10进制的互换:
printf %d 0x1b40
printf "0x%x" 6976
3. Cpu消耗高的分析方法
a. 找出对应的java进程pid:
ps -ef | grep java
b. 找出java进程中最消耗cpu的线程:
top -H -p <pid>
- 将找出的线程id转换为16进制
- jstack获取java的线程堆栈
- 根据16进制的id从线程堆栈中找到相关的堆栈信息
说明:线程堆栈中可以看出对应线程执行的是Java代码还是Native method
找不到对应的线程堆栈?
- 执行的Native method是重新创建的线程。
- 代码bug,堆内存耗完,jvm不断执行full gc。
- jvm自身bug😂。
垃圾收集的统计信息——查看Gc原因
jstat -gccause用于查看垃圾收集的统计信息,若有发生垃圾回收,还会显示最后一次以及当前发生垃圾回收的原因,它比-gcutil会多出最后一次垃圾回收的原因以及当前正在发生的垃圾回收的原因。
jstat -gccause pid 1234

