lxcfs
What is lxcfs
FUSE filesystem for LXC, offering the following features:
- a cgroupfs compatible view for unprivileged containers
- a set of cgroup-aware files:
- cpuinfo
- meminfo
- stat
- uptime
In other words, it will provide an emulated /proc and /sys/fs/cgroup folder for the containers.
Why use lxcfs
Background One
开发、运维:Cat显示的load不准啊,怎么回事啊?
Java获取系统负载:
import java.lang.management.ManagementFactory;
import java.lang.management.OperatingSystemMXBean;
public class SystemLoad {
public static void main(String[] args) {
OperatingSystemMXBean osBean = ManagementFactory.getOperatingSystemMXBean();
System.out.println(osBean.getSystemLoadAverage());
}
}
nodejs
Environment::GetCurrent()
Go
runtime.GOMAXPROCS()
Background Two
top
uptime
free -m
...
Question
为什么他们在物理机可以工作,而在容器中却会有一些问题?
当然,我们的第一反应会是这是docker造成的。
但是这话正确,但并非完全正确。准确的说,这些问题是由于docker的隔离性不足导致的。
这些问题的共同点其实在于它们依赖于一些系统文件。
| info | related file |
|---|---|
| cpu | /proc/cpuinfo |
| mem | /proc/meminfo |
| uptime | /proc/uptime |
| load | /proc/loadavg |
| cpu-online | /sys/devices/system/cpu/online |
解决方案与弊端
点评目前的解决方案:
- 修改linux相关code,如top、memory等。
弊端
-
为了在容器内准确查看linux的各项指标,就需要大动干戈修改linux code,万一出现bug怎么办?这不是一个可以被广泛接受的方案。
-
如果现在需要升级一个新的linux稳定版,又需要打上修改的补丁,重启物理机,这个工作量真是吃力不讨好。
其他公司的解决方案
- 修改linux系统通用软件包procps,以达到替换原有top、memory等命令。
- 并不允许开发或者运维登陆容器,自己研发一套容器的监控系统。
- 使用lxcfs。
- lxcfs引出的方案:熟悉了lxcfs之后,完全可以自己mount文件,从宿主机的角度模仿各项文件格式将各项指标算出来并写入,因为需要不停定时去算,相比lxcfs效率要低。
lxcfs使用和发展现状
-
项目发展历程Dec 7, 2014 – Mar 8, 2016,共发布23个版本
-
近两个月内github star数从30——>90
-
lxcfs对于docker内的监控来说还算是个半成品,需要自行扩展。
-
目前国内已知在生产环境使用的互联网公司:
- 蘑菇街
- 腾讯游戏
How to use lxcfs
FUSE
用户空间文件系统(Filesystem in Userspace,简称FUSE)是操作系统中的概念,指完全在用户态实现的文件系统。
目前Linux通过内核模块对此进行支持。一些文件系统如ZFS,glusterfs使用FUSE实现。
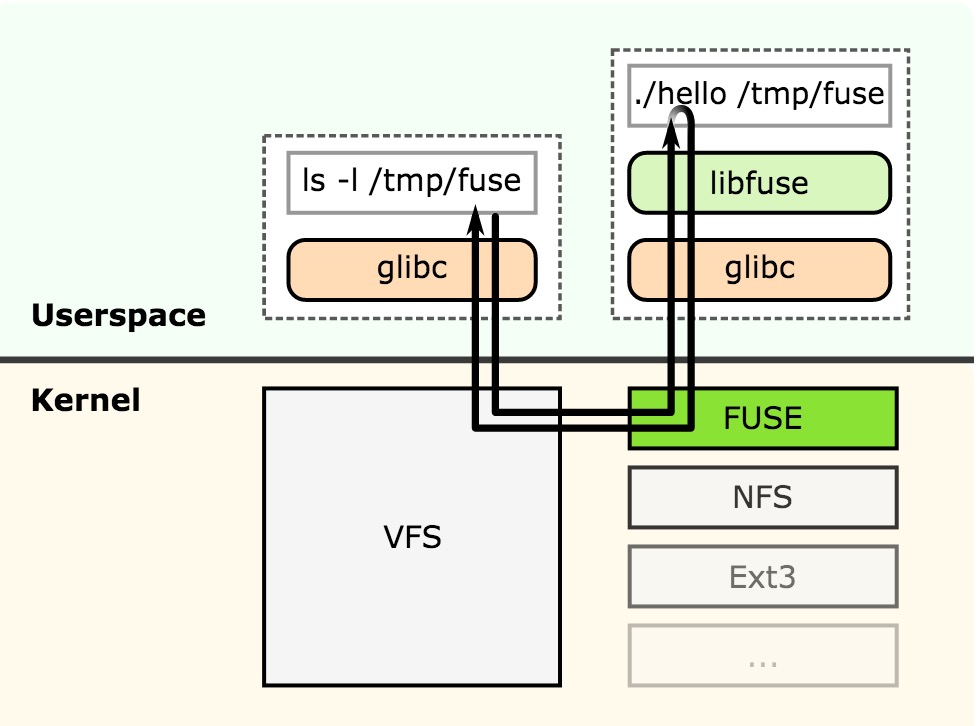
FUSE的工作原理如上图所示。假设基于FUSE的用户态文件系统hello挂载在/tmp/fuse目录下。当应用层程序要访问/tmp/fuse下的文件时,通过glibc中的函数进行系统调用,处理这些系统调用的VFS中的函数会调用FUSE在内核中的文件系统;内核中的FUSE文件系统将用户的请求,发送给用户态文件系统hello;用户态文件系统收到请求后,进行处理,将结果返回给内核中的FUSE文件系统;最后,内核中的FUSE文件系统将数据返回给用户态程序。
源码中简单的例子:hello.c
gcc -Wall -o hello hello.c `pkg-config fuse --cflags --libs`
mkdir /tmp/fuse
./hello /tmp/fuse
ls -l /tmp/fuse
编译运行
git clone git://github.com/lxc/lxcfs
cd lxcfs
./bootstrap.sh
./configure
make
sudo mkdir -p /var/lib/lxcfs
sudo ./lxcfs -s -f -o allow_other /var/lib/lxcfs/
启动容器
docker run -it --rm --privileged=true --cpuset=0,1 -v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw -v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw -v /var/lib/lxcfs/proc/stat:/proc/stat -v /var/lib/lxcfs/cgroup/:/cgroup/:rw -v /var/lib/lxcfs/cpu/online:/cpu/online:rw -v /var/lib/lxcfs/proc/loadavg:/proc/loadavg:rw ubuntu:14.04 /bin/bash
原理介绍
uptime
$ > cat /proc/uptime
3387048.81 3310821.00
第一个参数是代表从系统启动到现在的时间(以秒为单位):
3387048.81秒 = 39.20195381944444天,说明这台服务器已连续开机39.20195381944444天。
第二个参数是代表系统空闲的时间(以秒为单位):
3310821.00秒 = 38.3196875天,说明这台机器从开机到现在一共只有38天左右没事干。
空闲率高低并不意味着,它做的工作很多,跟服务器的配置和性能也有关系。
lxcfs实现容器内uptime的显示也是通过计算并修改这个文件的值来实现的。
load
cpu usage和load的区别:
1) 负载均值用来估量CPU利用率的发展趋势,而不是某一时刻的状况
2) 负载均值包括所有CPU的需求,而不仅仅是在测量时活跃的
CPU利用率 = 1 - 程序占用cpu时间/程序总的运行时间
我们如何理解CPU负载?一只单核的处理器可以形象得比喻成一条单车道!那么:
*** 0.00 表示目前桥面上没有任何的车流。
*** 1.00 表示刚好是在这座桥的承受范围内。
*** 超过 1.00,那么说明这座桥已经超出负荷,交通严重的拥堵。 那么情况有多糟糕?
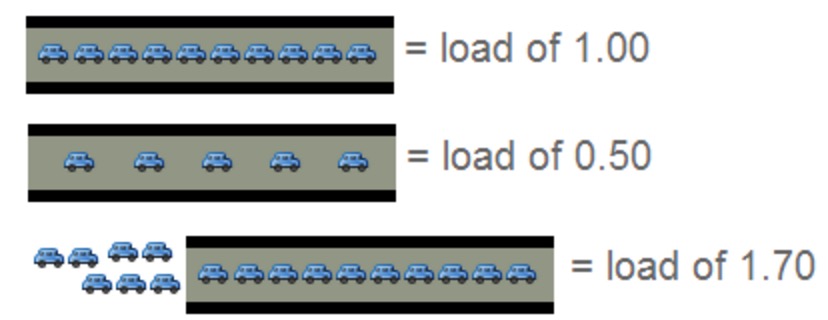
在多处理器系统中,负载均值是基于内核的数量决定的。

所以理想状态下,希望负载平均值小于等于Cpu核数。
linux计算load原理
$ > uptime
20:15:01 up 3:07, 6 users, load average: 0.43, 0.97, 1.05
$ > top
top - 04:00:56 up 37 min, 1 user, load average: 0.00, 0.01, 0.01
Tasks: 101 total, 2 running, 99 sleeping, 0 stopped, 0 zombie
........................
$ > cat /proc/loadavg
0.64 0.81 0.86 3/364 6930
每个值的含义依次为:
lavg_1 (0.64) 1-分钟平均负载
lavg_5 (0.81) 5-分钟平均负载
lavg_15(0.86) 15-分钟平均负载
nr_running (3) 在采样时刻,运行队列的任务的数目,与/proc/stat的procs_running表示相同意思
nr_threads (364) 在采样时刻,系统中活跃的任务的个数(不包括运行已经结束的任务)
last_pid(6930) 最大的pid值,包括轻量级进程,即线程。
linux内核里如何计算load的:
系统平均负载被定义:在特定时间间隔内运行队列中的平均进程数。
calc load代码段:
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point(定点) */
#define LOAD_FREQ (5*HZ) /* 5 sec intervals,每隔5秒计算一次平均负载值 */
#define CALC_LOAD(load, exp, n) \
load *= exp; \
load += n*(FIXED_1 - exp); \
load >>= FSHIFT;
unsigned long avenrun[3];
EXPORT_SYMBOL(avenrun);
static inline void calc_load(unsigned long ticks) {
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count += LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
负载初始化为0,假设最近1、5、15分钟内的平均负载分别为 load1、load5和load15,那么下一个计算时刻内核通过下面的算式计算负载:
load(t) = load(t-1) e^(-5/60) + n*(1 - e^(-5/60))
其中,exp(x)为e的x次幂,n为当前运行队列的长度。
Linux内核认为进程的生存时间服从参数为1的指数分布,指数分布的概率密度为:
以内核计算负载load1为例,设相邻两个计算时刻之间系统活动的进程集合为S0。从
1分钟前到当前计算时刻这段时间里面活动的load1个进程,设他们的集合是
S1,内核认为的概率密度是:λe-λx,而在当前时刻活动的n个进程,设他们的集合是
Sn内核认为的概率密度是1-λe-λx。其中x = 5 / 60,
因为相邻两个计算时刻之间进程所耗的CPU时间为5秒,而考虑的时间段是1分钟
(60秒)。那么可以求出最近1分钟系统运行队列的长度。
load1 = |S1| *(λe-λx) + |Sn| * (1-λe-λx)
lxcfs计算load思路:
由上面的分析可知,只要在用户态获取到当前运行队列的长度以及任务总数一切都迎刃而解。
进程满足什么条件可以位于运行队列之中?
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
Linux进程的几种状态:
R (TASK_RUNNING),可执行状态。
S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
Z (TASK_DEAD – EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
X (TASK_DEAD – EXIT_DEAD),退出状态,进程即将被销毁。
踩坑1:
/proc文件夹下有所有进程号,通过编译内核模块与linux内核通信,拿到task数据结构,得到该进程下的所有线程以及线程状态。
结果:有些内核版本并不好使,放弃。
踩坑2:
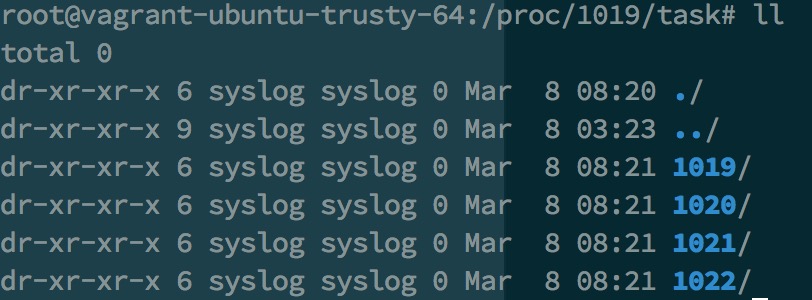
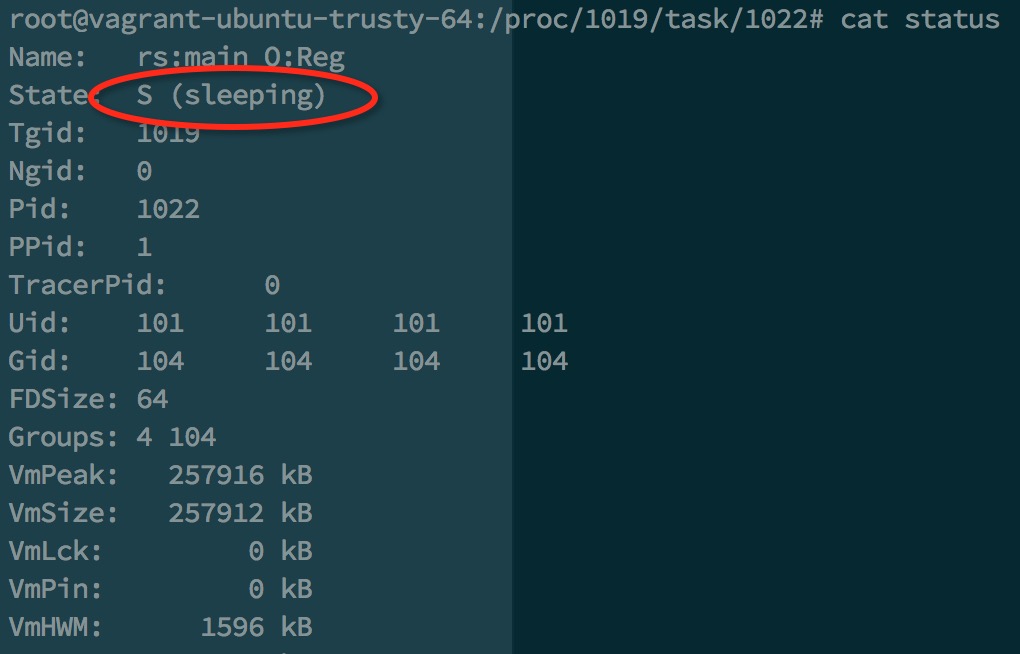
利用liunx内核dump下来的数据计算。/proc/{process}/task/下存有所有进程下的所有线程,/proc/{process}/task/{thred}/status存有线程的状态(如下图)。
结果:验证可行,lxcfs可以开始扩展了!(过一遍lxcfs修复load后的代码吧)
踩坑3:
上面有提到,理解了lxcfs的做法,完全可以使用类似的方法替代它,编程语言也不受限制。挂载需要的proc、cgroup等文件,从宿主机的角度计算每个容器的各项指标值,按照linux的文件格式内容写入挂载的文件。
结果:验证可行,缺点就是每个指标都要定时不停算,效率比lxcfs要低。
参考资料
https://github.com/lxc/lxcfs/

